Topic Modelling
Methods to model topics for documents
Introduction
Scientific advancement and improvement in living standards and education has historically resulted in information explosion. With the advent of the internet, pace of more accessible information had become ever more accelerated. Therefore tools to find and discover the information we seek is of utmost importance.
Topic modelling is a method to infer the thematic structure of a document such that automatic tools to organise, search and summarise information can be devised. Documents are generated as a collection of topics. These topics are conveyed in paragraphs, sentences and words without specific topical structure being drawn out, or specifying what topics are covered by a given document. Human reading a document can intuitively ascertain what the topics are using the prior worldly knowledge. Topic modelling attempts to give this ability to an algorithm such that large amount of documents can be processed, organised and be made available in the form of search, for human consumption.
Topic modelling is a statistical method to discover the topics that occur in a collection of documents. The modelling algorithms generally require no annotated data rather topics emerge from the data itself. (There are some supervised algorithms (LabeledLDA) in recent times to exploit the tagged documents, specially social bookmarking websites (Ramage, D., Hall, D., Nallapati, R., & Manning, C. D. (2009, August)).
The advantages of topic modelling allows the following to name a few:
Model the evolution of topics over time giving an understanding and ability to predict for the future.
Model associations and hierarchies of topics allowing a broader picture of a domain
Discover influential articles and predict links between them
Characterize political decisions Organize and browse large corpora (e.g. Wikipedia) [ref: https://www.cs.princeton.edu/~blei/kdd-tutorial.pdf]
In this essay we would look at two approaches to topic modelling, namely Latent Dirichlet Allocation (LDA) and Pachinko Allocation Model (PAM). LDA is a well known method of topic modelling, first introduced by Blei, D. M., Ng, A. Y., & Jordan, M. I. (2003). PAM can be thought of as an improvement over LDA introduced by Li, W., & McCallum, A. (2006, June).
Latent Dirichlet Allocation
LDA is a generative statistical method where observations are explained as a function of a collection of hidden random variables. Each document can be thought of as a small finite mixture of topics (collection of hidden random variables), from which the words are generated. In other words, a topic can be modelled as a statistical distribution of words and a document in turn as a distribution of topics. In LDA, statistical distribution of the topics is assumed to have a Dirichlet distribution. Dirichlete distribution describes a distribution over probability distributions [see https://www.hiit.fi/u/ahonkela/dippa/node95.html]
Each document in a corpora can be thought of as generated by the following process:
- Randomly choose a topic distribution
- Randomly choose a topic from the chosen topic distribution
- Randomly choose a word from the word distribution of the topic
The goal of the LDA topic modelling is to infer these distributions from the observed documents.
Main advantage of formulating LDA as a probabilistic model is that it can be used as a component in a more complicated modelling pipeline. LDA has been extended and adapted in many ways. LDA makes some statistical assumptions about the corpus. One such being the 'bag of words' assumption, where it assumes invariance to the order of the words. This is an unrealistic simplification but reasonable if the goal is just to find the semantic structure of a document (Blei, D. M. (2012)), but makes it unsuitable for language generation tasks, such as summarisation. Another assumption of LDA is that it is invariant to the order of documents. This may be unrealistic when analysing a collection of documents that has a specific order, for example, legal documents that has a significant reliance on the order or in situations where there's a need to analyse the changes of topics over time. One more assumption being that the topics are known and they are fixed. Also, LDA assumes no correlation between topics, but for example, a document about rocket propulsion is more likely to contain topics of physics or chemistry than gardening. This type of correlations are allowed in PAM.
Variations on LDA have been used in other areas unrelated to natural language processing, such as bioinformatics (Pinoli, P., Chicco, D., & Masseroli, M. (2014, May)) and image labelling (Fei-Fei, L., & Perona, P. (2005, June)). In the case of image labelling, image was assumed to be the document and small patches of the image to be the words.
Pachinko Allocation Model (PAM)
PAM is an improvement over LDA, where the latter fails to capture correlations among topics. In reality topic correlations are very common and being unable to detect the correlations put LDA at a disadvantage with regards to performance, ability to discover large number of fine grained and tightly coherent topics. LDA can also combine arbitrary sets of topics which yields nonsensical results (Li, W., & McCallum, A. (2006, June)).
In PAM, the concept of topics are extended to be distributions over words and other topics. This is represented by a directed acyclic graph (DAG) where topics are represented by internal nodes and words from a vocabulary, are represented by the leaves. Therefore LDA simply can be represented by a three level hierarchical structure where a root node associated with a Dirichlet distribution, its child nodes representing topic distributions and each topic node having leaves that represent a vocabulary over words. In this regard, PAM is a superset of LDA.
In their paper 'Pachinko Allocation' (Li, W., & McCallum, A. (2006, June)), describe experiments where PAM is evaluated against LDA for a topic discovery task. The following descriptions of the experiments are extracts from their paper.
In this task, they used randomly selected 1647 research paper abstracts from a large collection as their dataset. PAM was configured to have 4 level structure, where it includes a root, set of super-topics and set of sub-topics. As LDA can be modelled as a three level hierarchy, sub-topics in the PAM structure were treated as same as for LDA. This produced a hierarchical topic set (50 super topics,100 sub topics) for PAM and for LDA, 100 topics. Resultant topics (represented by their word distributions) anonymised and randomised and presented to 5 human judges to be evaluated on the semantic coherence and specificity. The results summarised in Table 1 shows that, PAM had more topics better judged than LDA.
| Votes | LDA | PAM |
|---|---|---|
| 5 | 0 | 5 |
| `>=4 | 3 | 8 |
| `>=3 | 9 | 16 |
Table 1 (Human judgement results. For all categories)
In addition to the above, they conducted a likelihood comparison between PAM, LDA and other similar methods. In this experiment they learned the model from a training set and computed the likelihood for a test set. Training and test sets were split 3:1 ratio from the same dataset as before. They used a nonparametric likelihood estimates based on empirical likelihood (EL) (Diggle, P. J., & Gratton, R. J. (1984)). They first generated 1000 random documents from the trained model and estimated a multinomial distribution from each sample directly from the sub topic mixture. Likelihood of the test document was calculated as its average probability from each multinomial. Results showed that compared to LDA, PAM always produced higher likelihood across a range of sub-topic numbers (Figure 1). LDA performance peaks at 40 topics and PAM at 160 sub-topics, thus PAM can support larger number of topics.
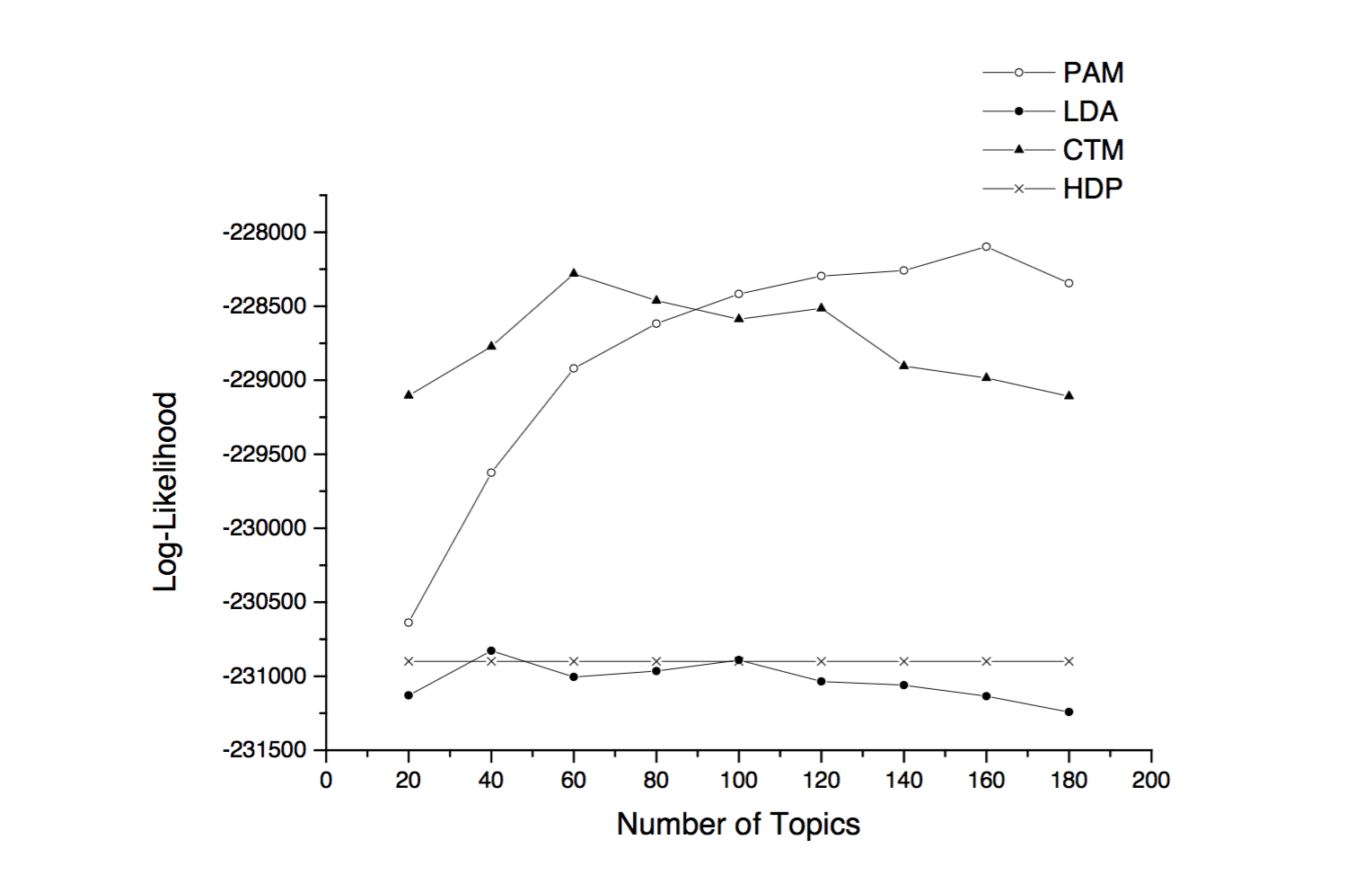
Figure 1 Likelihood comparison with different numbers of topics
Another comparison made was in document classification. The experiment was to classify documents from 20 newsgroups containing 4836 documents into 5 classes. As before, training and test sets were split 3:1 ratio. Models were trained for each class and likelihood was calculated for the test data. Table 2 shows the classification accuracy, and according to the sign test, improvement of PAM over LDA is statistically significant (p-value < 0.05).
| Class | No of Docs | LDA | PAM |
|---|---|---|---|
| graphics | 243 | 83.95 | 86.83 |
| os | 239 | 81.59 | 84.10 |
| pc | 245 | 83.67 | 88.16 |
| mac | 239 | 86.61 | 89.54 |
| windows.x | 243 | 88.07 | 92.20 |
| total | 1209 | 84.70 | 87.34 |
Table 2 (Document classification accuracy %)
In conclusion, PAM has advantages on LDA on quality of the topics as it is more expressive and has more realistic assumptions. Compared to PAM, LDA is much simpler and as evidenced in the NLP research, large number of extensions have sprung up. LDA can be thought of as a good basis for further research into topic modelling.
Further work
Deep neural networks are increasingly used in a wide variety of problems with surprisingly good results. Success of this is largely due to the exploitation of large amount of data and comparable amount of processing power. In the paper 'Modeling documents with deep Boltzman machine' (Srivastava, N., Salakhutdinov, R. R., & Hinton, G. E. (2013)) describes such an application. Topic modelling is a challenging area, and no single method completely captures the complexity of real world language representations. The advantage of deep networks are that, they could be trained to contain a multitude of the techniques that can be automatically selected from the data itself.
References
Ramage, D., Hall, D., Nallapati, R., & Manning, C. D. (2009, August). Labeled LDA: A supervised topic model for credit attribution in multi-labeled corpora. In Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing: Volume 1-Volume 1 (pp. 248-256). Association for Computational Linguistics.
Blei, D. M., Ng, A. Y., & Jordan, M. I. (2003). Latent dirichlet allocation. the Journal of machine Learning research, 3, 993-1022.
Li, W., & McCallum, A. (2006, June). Pachinko allocation: DAG-structured mixture models of topic correlations. In Proceedings of the 23rd international conference on Machine learning (pp. 577-584). ACM.
Fei-Fei, L., & Perona, P. (2005, June). A bayesian hierarchical model for learning natural scene categories. In Computer Vision and Pattern Recognition, 2005. CVPR 2005. IEEE Computer Society Conference on (Vol. 2, pp. 524-531). IEEE.
Pinoli, P., Chicco, D., & Masseroli, M. (2014, May). Latent Dirichlet Allocation based on Gibbs Sampling for gene function prediction. In Computational Intelligence in Bioinformatics and Computational Biology, 2014 IEEE Conference on (pp. 1-8). IEEE.
Blei, D. M. (2012). Probabilistic topic models. Communications of the ACM,55(4), 77-84.
Srivastava, N., Salakhutdinov, R. R., & Hinton, G. E. (2013). Modeling documents with deep boltzmann machines. arXiv preprint arXiv:1309.6865.
Diggle, P. J., & Gratton, R. J. (1984). Monte Carlo methods of inference for implicit statistical models. Journal of the Royal Statistical Society. Series B (Methodological), 193-227.